先捋一下网络架构,用户的请求通过下面的这条路径到达 Tracker 服务:
用户 <-- CloudFlare --> BuyVM(中继服,抗DMCA) <-- UFW+WireGuard --> Netcup(后端服) <-- --> Trunker(实际服务)
两台服务器之间使用 WireGuard 互联,并使用 UFW 进行内核态转发以最大程度改善性能。(1C1G 每一个 CPU 指令都得精打细算啊……之前试了几个用户态代理都根本顶不住这样的并发量……)
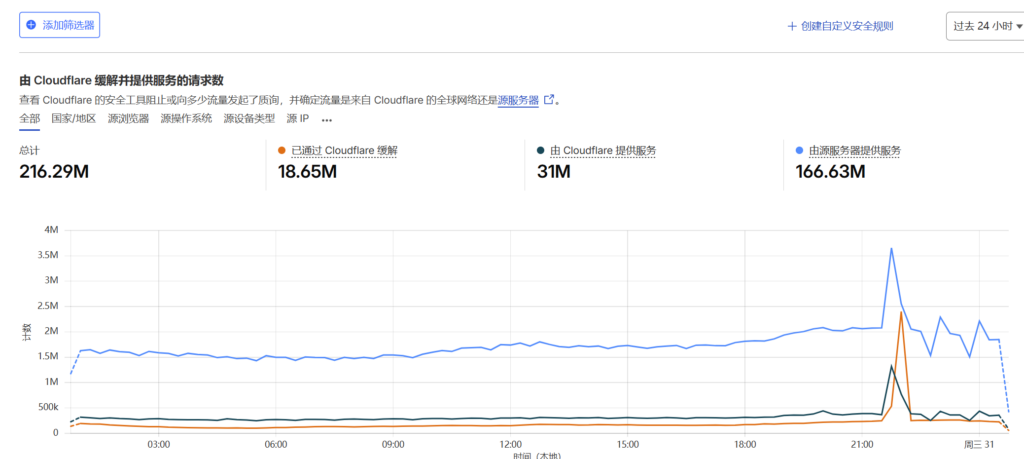
今天早些时候,遇到了一次 DDoS 攻击,大量无效请求涌入 Trunker,攻击其 websocket 端点和 HTTP Announce 端点,并直接导致 Trunker 崩溃下线。
攻击时单机每秒请求数从平时的 ~2000req/s 飞涨到超过 5000req/s,然而又因为 Trunker 崩溃下线,大量 CloudFlare 的回源 TCP 连接卡在 BuyVM 设备上,CPU 中断暴涨起飞并最终引发 BuyVM 一起宕机。

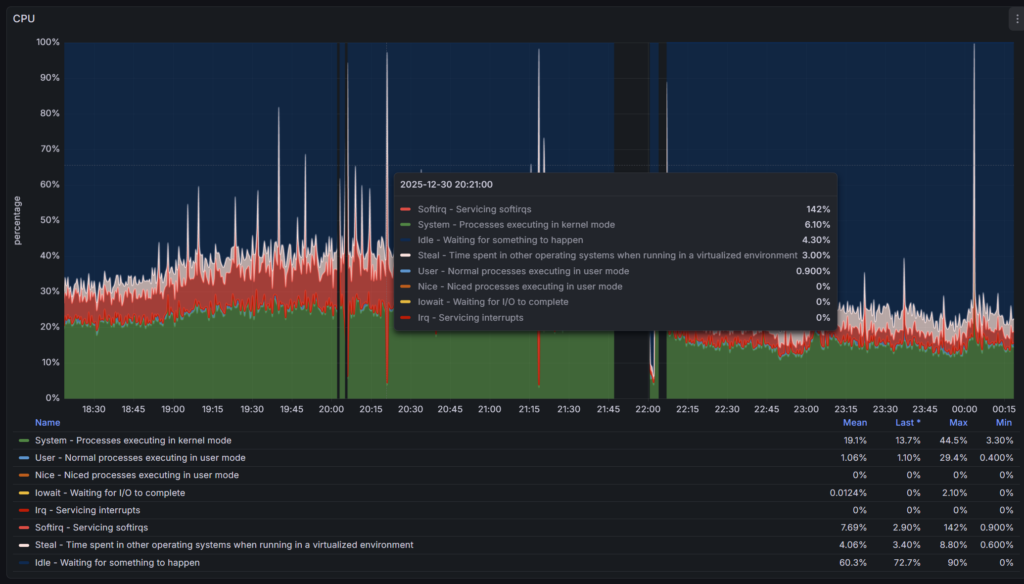
尽管后续通过一些调整解决了 Trunker 崩溃的问题,但是 BuyVM 卡死的问题已经不是第一次发生——每次 Trunker 服务挂掉的时候,BuyVM 都会直接因大量连接卡死。更加雪上加霜的是一旦请求失败,qBittorrent 等这类客户端会重试 announce,短时间内请求数就会翻翻。即使强制重启系统,也会因为涌来的重试连接再次挤压崩溃。
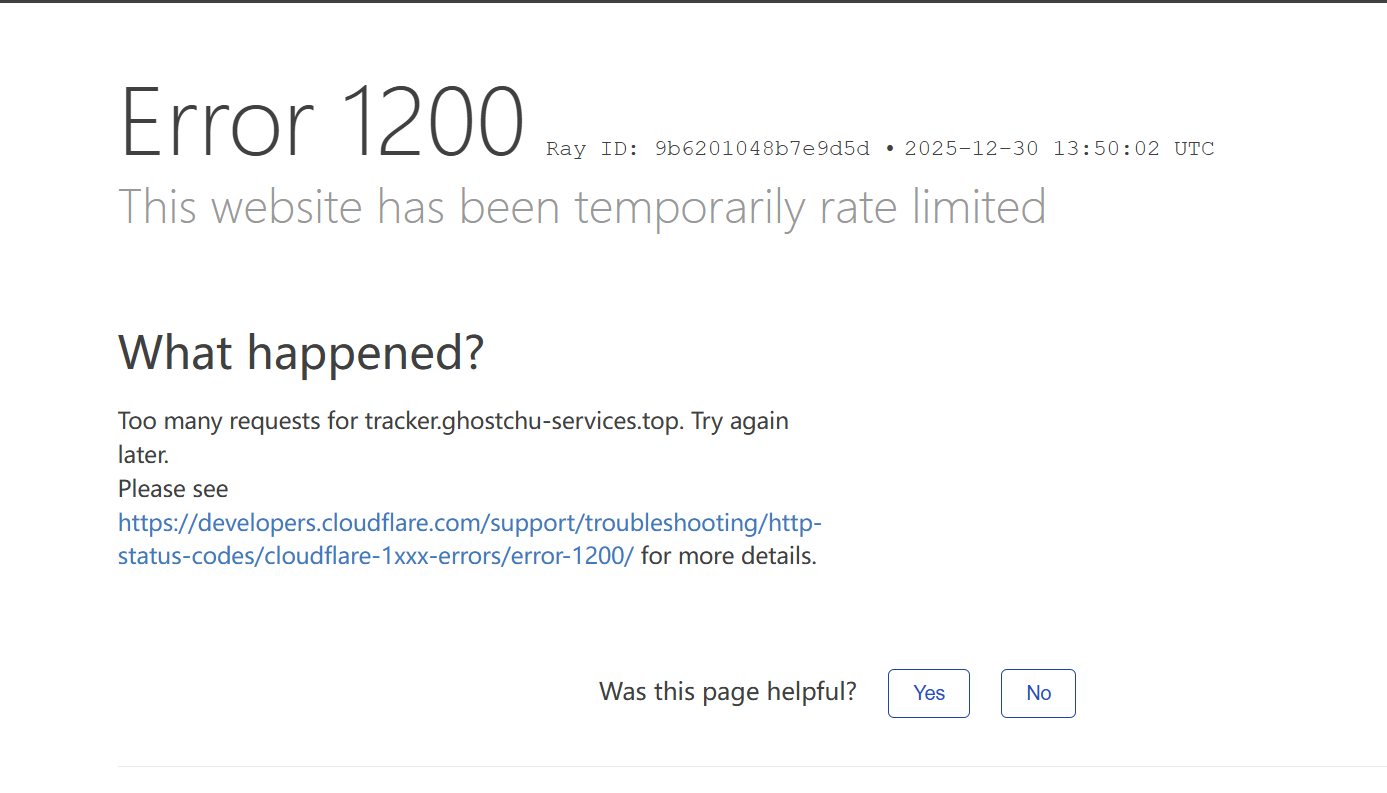
最后,大量请求堆积甚至压垮了 CloudFlare,域名被强制速率限制。
缓解问题
由于大量连接的涌入,服务器一旦重启就会立刻高负载立刻趴下。好在所有用户流量都要首先经过 CloudFlare,因此立刻在 CloudFlare 上部署安全规则阻断所有 Announce 请求,为服务修复争取时间,切断流量。
经过简单的日志分析,初步判断 Trunker 的 WsServer 和 HTTP Tracker 遭到了攻击,并且 WsServer 受到影响最大,每秒上百条报错日志淹没了 Portainer 控制台,Docker 服务进程也因处理高频日志而占用大量 CPU。因此首先禁用 WsServer,然后拉起 Trunker 进程,否则稍后 BuyVM 一旦重启并放行流量,又会因为 Trunker 未运行堆积 TCP 连接再次宕机。
Trunker 就绪后,着手处理 BuyVM。在此先分析一下 Announce 请求的性质。
BitTorrent Tracker 的 Announce 请求本质上是一个 HTTP GET 请求,通过查询字符串传递参数并获取 Peers 响应。为了支持 IPV6,现代下载器都会选择从本机设备上的每一个网络接口向 Tracker 发送一次请求。一台机器的一个种子 Announce 就能发出数个甚至更多的请求,更别提如果你做种了上千个种子。这是典型的高并发场景。
一个 Announce 请求结束后,连接就会被销毁,生命周期结束。单个请求生命周期如果网络通畅则通常不超过 5 秒钟。对于 Trunker 来说,处理单次 Announce 耗时通常不超过 2ms,而且两个服务器的数据中心之间连接良好,速度够快。因此 5 秒钟绰绰有余。

CloudFlare 的存在能够继续优化这个场景,因为有时回源可以在单一源站连接中处理多个 HTTP 请求,减少需要和源站服务器进行 TCP 建联的次数。
但是在今天的这个场景下,由于后端服务器挂掉,CloudFlare 只能等待超时才能继续处理下一个请求,因此 CloudFlare 的边缘服务器选择开启更多连接直至达到速率限制。大量边缘服务器开启的大量连接配以高并发请求量,瞬间就会摧毁 1C1G 小机器。
解决方案是让 TCP 连接快速失败,至少不要因为后端服务挂掉把中继服务器一起拖下水。如果 TCP 连接建联时间超过 Announce 请求生命周期,就立刻关闭(核心思想是反正也连不上了干脆就放弃挣扎)。而 CloudFlare 则会立刻结束处理,断开连接,避免消耗完 CloudFlare 上的域回源连接池导致被直接 rate limit。
可以通过 sysctl.conf 来修改内核的 TCP 参数:
nano /etc/sysctl.d/99-Tracker.conf
net.ipv4.tcp_tw_reuse = 1
net.netfilter.nf_conntrack_max = 262144
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 6
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 6
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 10
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 10
net.netfilter.nf_conntrack_tcp_timeout_last_ack = 10
net.ipv4.tcp_max_syn_backlog = 10000
net.ipv4.tcp_abort_on_overflow = 1
net.ipv4.tcp_syncookies = 1这样如果和后端迟迟建立不了连接:
- 原来 30 秒甚至 60 秒的超时,现在可以缩短到 6~10 秒。更短的超时可以大量减少等待的连接数。
- 当连接队列已满时,会主动发送 RST 重置 TCP 连接,以便 CloudFlare 立刻响应错误页面,而不是一直装死等待连接方重试。
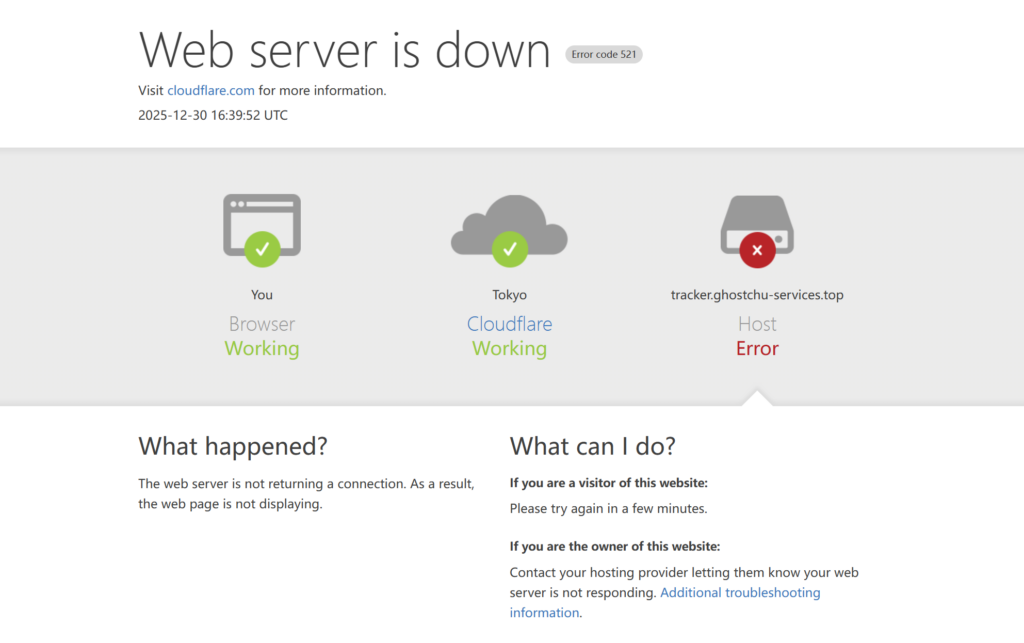
sysctl -p /etc/sysctl.d/99-Tracker.conf 使其生效,然后手动关闭后端 Trunker 服务看看效果。
经过参数调整,现在 Web server is down 几乎是瞬间返回,BuyVM 的 CPU 也没有明显变化,且没有卡死。后端服务恢复后,也几乎可以立即恢复正常响应和服务。
至此,紧张刺激的抢修结束,又是和平的一天。